このサイト(mh4gf.dev)で llms-full.txt を新たに提供し始めました。 https://mh4gf.dev/llms-full.txt から直接アクセスできます。
mh4gf.dev は私の個人サイトで、自己紹介や職務経歴書、ブログ記事などをまとめています。 llms-full.txt ではそれらを 一枚のマークダウンテキスト として出力しています。
本記事では、llms-full.txt とは何か・なぜ llms-full.txt を提供し始めたのか、そして Next.js を使った実装方法について紹介します。
llms.txt / llms-full.txt とは何か
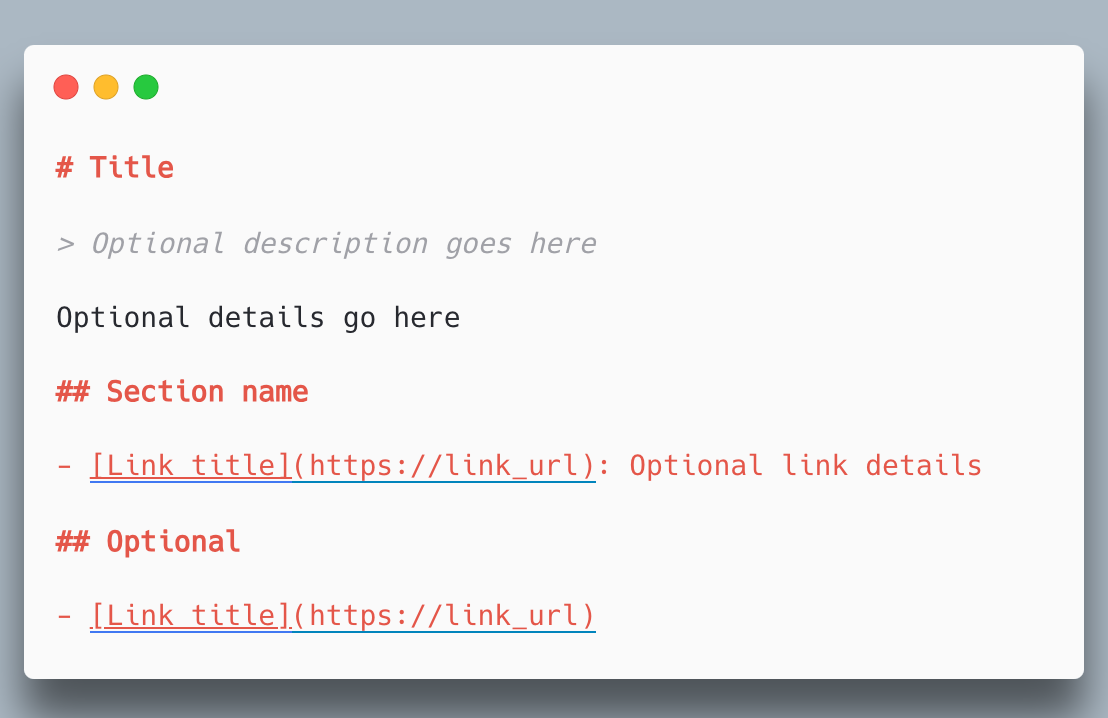
llms.txt とは、サイト上の重要なドキュメントや概要をまとめておき、生成 AI(LLM)がそれを読み込むことでサイト全体の情報を把握しやすくするためのファイル形式です。
提案者は Answer.AI の共同創業者である Jeremy Howard 氏であり、Anthropic や Cursor といった LLM 系ツール、また Zapier などもサポートしています。llmstxt.site には、サポートしているサイトや事例が一覧で掲載されています。
似たような目的のファイルとして sitemap.xml があります。こちらは検索エンジン向けに「すべてのページの一覧」を提供するファイルですが、llms.txt は LLM が理解しやすいフォーマット(マークダウン形式)で書かれ、サイトマップより 自由度が高い のが特徴です。
たとえば、外部サイトへのリンクを含めたり、ページの目次や概要のような人間の文章を追加しても問題ありません。
提案には llms.txt と llms-full.txt という二つの目的のファイルが含まれており、これらの違いは以下です。
- llms.txt … 目次や概要のように、サイト全体を俯瞰できるエッセンスのみをコンパクトにまとめたもの。小さなトークン数でサイトの全体像を LLM に把握させ、ユーザーの質問に最適なドキュメントページの URL をクイックに返却するなどの用途が想定されています。
- llms-full.txt … 全ドキュメントや全記事を ほぼ全文 入れ込んだ大容量ファイル。すべての情報をコンテキストに入れ、ユーザーの質問に対して参照先の URL を返すのではなく回答を直接返す用途が想定されています。
このサイトの場合、全文を入れ込んでもそこまで大量なトークン数にならず、また「すべてをまとめて一気に LLM に渡したい」というニーズが大きかったので、より大容量の llms-full.txt を作っています。
このサイトで提供し始めた理由は?
大規模コンテキストウィンドウ時代の活用
OpenAI の GPT-4o は 128,000 トークン、o1 は 200,000 トークン までコンテキストに含められると ドキュメントで説明 されています。
私の用意した llms-full.txt は、OpenAI Tokenizer で計測したところ 57,385 トークン / 121,192 文字 でした。(2025/01/04 時点)
丸ごと読み込んでも GPT-4o なら余裕があり、コピー&ペーストし LLM に全文を食わせても余裕を持って会話できます。
業務プロダクトでの活用
もともとは仕事で関わっているプロダクト開発でも llms-full.txt が役立つのではないか、という発想がありました。
私は Product Required Document やインセプションデッキなどの情報を LLM に投げ込み、コンテキストを理解してもらった上で開発方針やユーザーインタビュー設計など多くの場面で相談しています (もちろん LLM への情報漏洩に気をつけています)。しかし、
- 毎度必要な情報を手作業でコピペするのは面倒
- ChatGPT の GPTs や Dify などで RAG(Retrieval Augmented Generation)の仕組みを構築しても、情報の更新が大変
…という課題がありました。
そこで 「/llms-full.txt を常に自動生成しておき、必要に応じてまるっとコピペして会話する」 という運用は、かなりシンプルで手軽だと感じました。ユーザーマニュアルや周辺情報を LLM が解釈しやすい状態に保守しておき、常にマークダウン 1 枚にまとめられるようにしておく形です。
/llms-full.txt というパスでパブリックに公開せずとも、CI/CD でチーム向けに生成し手動で注入するコンテキストとして活用することは、本格的な検索システムを導入せずとも疑似的に RAG 的な運用ができ、プロダクト開発の効率化につながるのではないかと考えています。
パーソナルなサイトを LLM に読ませる価値
個人サイトであっても、以下のような用途があると考えています。
- レジュメのフィードバックやキャリア相談
- 自分風の記事を生成する補助 ... 自分が過去に書いたブログをすべて読ませて、文体やテーマを踏襲した記事下書きを作成してもらう
llms.txt が広く流通すれば、LLM が Web サイトにアクセスする際に優先的に利用されるといった状況も考えられますが、現時点では誰かに活用してもらうというより、自身の情報を整理し自分自身のために活用できそうです。
実装方法
続いては実装方法を紹介します。このサイトは Next.js で構築し、ブログ記事をマークダウンテキストで記載、contentlayer で読み込んで取得しページを生成しています。
今回は以下の要件があったため、Next.js の API Route を利用して実装しました。
/llms-full.txtといった拡張子つきのパスで提供したい- Content-Type を
text/plainでレスポンスを返却したい
サンプルコード
以下は実際の簡易版サンプルです。
import { NextResponse } from "next/server";
import { allArticles } from "@/.contentlayer/generated";
import { externalArticles } from "../_features/articles/data";
import { compareDesc } from "../_utils";
import { me } from "../_constants";
// 情報を集めてきてマークダウン形式で出力
const content = `
# ${me.name}
> ${me.description}
## Work Experience
${me.workExperiences
.map((work) => {
return `
### [${work.company.name}](${work.company.url})
- ${work.period}
- ${work.company.position.join("\n- ")}
`;
})
.join("\n")}
## Articles
${allArticles
.sort((a, b) => compareDesc(a.publishedAt, b.publishedAt))
.map((doc) => `### ${doc.title}\n${doc.body.raw}\n`)
.join("\n\n")}
## External Articles
${externalArticles.map((doc) => `- [${doc.title}](${doc.href})`).join("\n")}
`;
export function GET() {
return new NextResponse(content, {
headers: {
"Content-Type": "text/plain; charset=utf-8",
},
});
}このように、文字列テンプレートの中で 自分のデータ(自己紹介・経歴・記事など)をマークダウン形式で出力し、text/plain で返すだけです。contentlayer 経由で取得しているため、コンテンツが更新されたとしても自動的に反映することができます。
実際のコードはこちらです。
まとめ
- llms.txt / llms-full.txt とは、LLM に対してサイト情報を提供するための新しい標準として提案されているファイルフォーマット
- 大規模なコンテキストウィンドウを持つモデルが使えるようになったため、簡易的な RAG としての利用が便利
- Next.js で提供する場合は API Route で実装する